Automatic OCR with Hazel and PDFPen
I have a useful scanner as part of my networked HP printer that will scan directly to a shared directory on my computer. Once there, I want the file to be renamed to the current date and the document OCR’d so that I can search it.
To do this, I use Hazel and PDFPen and this is a note to ensure that I can remember to do it again if I ever need to!
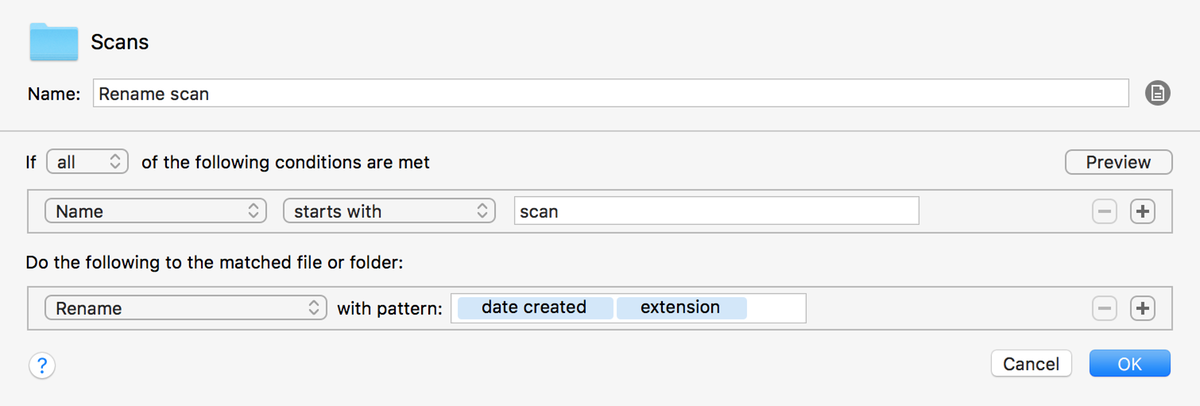
Firstly, rename the file. My scanner names each file with the prefix scan, so the Hazel rule is quite simple:
If all the following conditions are met:
Name starts with scan
Do the following to the matched file or folder:
Rename with pattern: [date created][extension]
This is the screenshot:
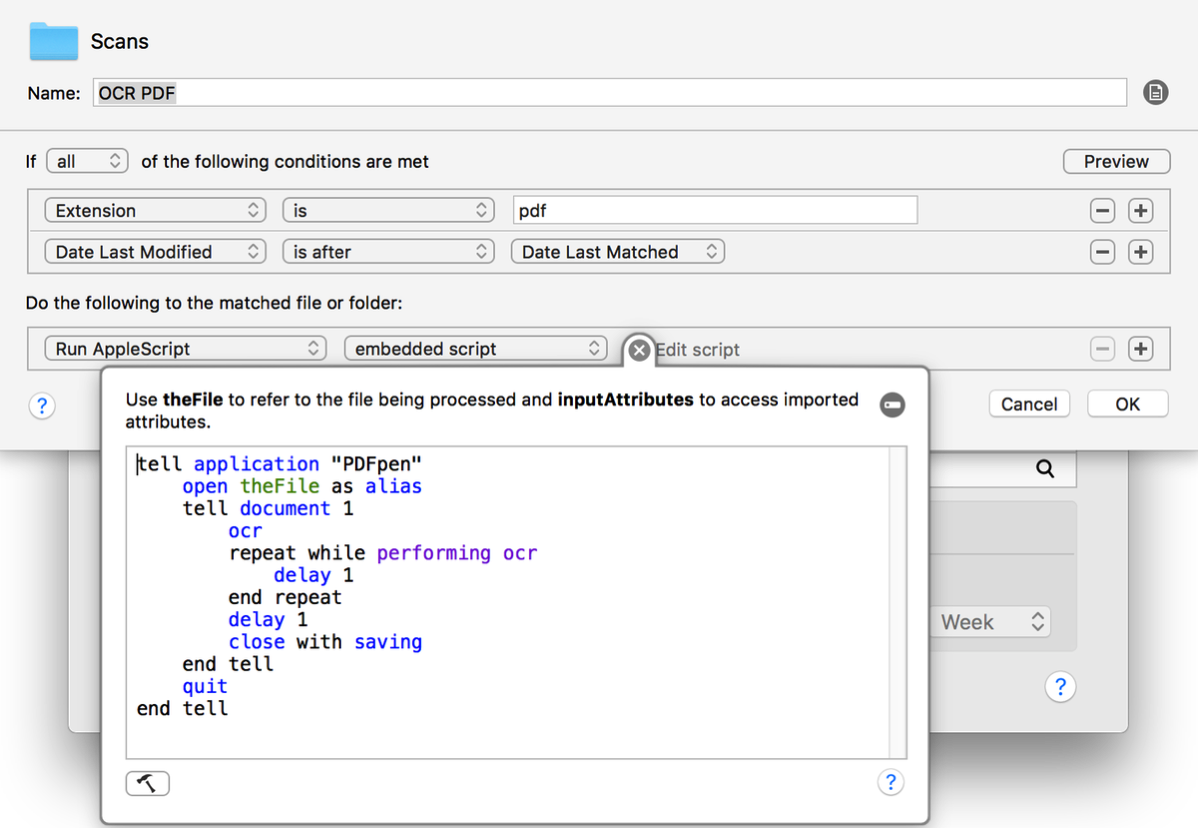
Having renamed the file, we can use PDFPen’s AppleScript support to perform an OCR of the document:
If all the following conditions are met:
Extension is pdf
Date Last Modified is after Date Last Matched
Do the following to the matched file or folder:
Run AppleScript embedded script
The embedded AppleScript is:
tell application "PDFpen"
open theFile as alias
tell document 1
ocr
repeat while performing ocr
delay 1
end repeat
delay 1
close with saving
end tell
quit
end tell
This is the screenshot of it in Hazel:
That’s it. Scanning a document now results in a dated, OCR’d PDF file in my Scans folder.



Is there a way to determine if the pdf has already undergone OCR?
Thanks.
The only way I know is to add a tag to the file.
Hi ,
I don't know how to get it to work yet – but one should be able to test if the doc has already been ocr'ed by testing the property of a document
needs ocr (boolean, r/o) : Does application think the document is a candidate for OCR?
Thanks
Iain.
And I scroll down and Andre Fixed it!
Thanks!!
Or in Hazel do a check to see if the document contents contain one of the following a, e, i, o u = if the document has an OCR layer then hazel should find a vowel (how good/accurate the OCR has been is a different matter)
I like this idea, Phil!
Hello Rob,
well, I am going to built up my own automation with Hazel, Devonthink Pro etc. Right now I have a small working solution which use PDFPenPro for OCRing. But if you import documents directly by Devonthink, Devonthink starts for OCR the Abbyy FineReader, which belongs to Devonthink.
Do you know, which application is the best for OCR? And if Abby FineReader is the best, how can I call this application in the AppleScript to do the job?
Kind regards,
Michael
Michael,
I have no idea which application does OCR best. I find PDFPen good enough for my needs.
I found a solution for finding out if the ocr must be started: "if needs ocr then". Works for my old PDFpenPro.
See the following script (I hope it is correctly formatted).